The presence of content on Google is not simply a consequence of its publication but the result of a complex technical process that includes stages of discovery, data collection and algorithmic processing. In the context of the number of digital content exploding, Tan Phat Digital noticed that Google has become more strict in choosing what is worthy of being stored in its index. For website administrators and SEO experts, identifying unindexed articles is a top priority task, because a website that is not indexed means it is completely invisible to potential users. This process requires a multi-layered checking system, from simple manual operations to the application of application programming interfaces (APIs) and server log analysis to find invisible barriers that are blocking the flow of data.
Methodology system for determining indexing status
To answer the question of checking unindexed articles, Tan Phat Digital recommends a hierarchical approach from the micro to macro, using formal tools in combination with big data analysis solutions.
Direct query techniques using search operators
The site: operator is a classic tool but still provides immediate diagnostic value. By using the site:yourdomain.com/url-bai-viet syntax, you can receive immediate feedback on Google's attribution status. Here are common techniques:
Domain-wide tests (Example:
site:sapo.vn): Helps estimate the total number of pages indexed by Google across the entire website.Specific URL tests (Example:
site:sapo.vn/abc-la-gi): Key verification Determine the index status of a single article.Check directories (For example:
site:domain.com/blog/): Evaluate Google's coverage in a specific category such as news or blog categories.
Experts at Tan Phat Digital note that the result from the site: operator is an estimate and may have a delay. Synchronization between servers. Therefore, this should only be considered an initial screening step.
Harness the power of Google Search Console
Google Search Console (GSC) provides the most accurate data because it comes directly from Google's internal database. The "URL Inspection" tool is the standard for determining why a post has not been indexed. When entering a URL, the system returns a detailed status: "URL is on Google" or "URL is not on Google".
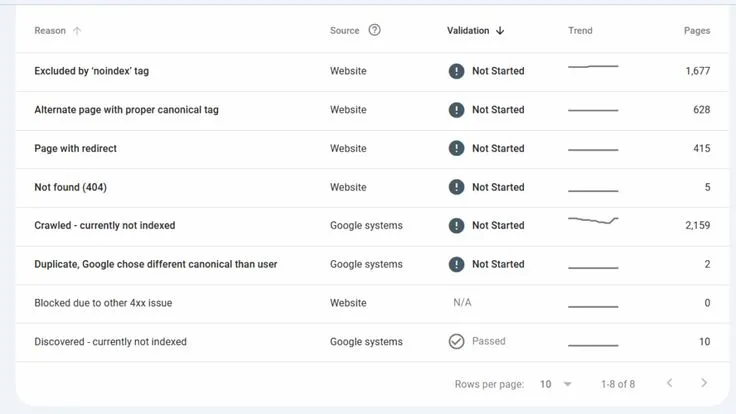
An important aspect is the "Pages" report in the "Indexing" section. Here, Google clearly classifies the reasons why articles are excluded. Analyzing this chart allows Tan Phat Digital's technical team to identify system errors instead of just checking each individual article.
Bulk Index Checking
For large websites, manual checking is impossible. Bulk checking solutions have become an essential part of modern SEO operations:
Use specialized tools: Screaming Frog SEO Spider, JetOctopus or Sitechecker allow integration with GSC's API to check the index status of the entire list of URLs in the sitemap.
Orphan page detection: This process helps find pages that exist but there are no internal links pointing to it, making it difficult for Googlebot to find or not prioritize indexing.
In-depth analysis of non-indexing statuses
Understanding Google's terminology is the key for Tan Phat Digital to provide accurate corrective measures.
List of common indexing statuses
Explored - Currently not indexed (Discovered - currently not indexed): Google already knows the URL (through the sitemap or the link pointing back) but has not yet accessed it to read the content. The cause is often due to low data collection budget or weak main machine. The solution is to enhance internal links and optimize server response speed.
Crawled - currently not indexed: Googlebot visited and downloaded the content but decided not to index it. The cause is often due to thin, duplicate content or lack of value. Need to upgrade the content quality and check the Canonical tag again.
Blocked by 'noindex' command (URL marked 'noindex'): The article is blocked directly in the source code or SEO plugin configuration. It is necessary to check the HTML code and remove the noindex tag on important pages.
Soft Error 404: The page displays error or empty content but still returns a 200 status code successfully. Need to add content or 301 redirect to the appropriate page.
Technical and infrastructure barriers
Besides content, a variety of technical errors can make the article "invisible" to Googlebot.
Errors in the Robots.txt and.htaccess configuration files
The robots.txt file is the first guide bot reads when accessing. An error like Disallow: //code> can block an entire website. Tan Phat Digital recommends periodically checking this file to ensure that important folders are not blocked by mistake. In addition, server or firewall configuration sometimes mistakenly recognizes Googlebot as a DDoS attack and blocks access (error 403), leading to indexing interruptions.
Mobile-First Indexing and Page Experience
Google prioritizes the mobile version to evaluate websites. If the article has errors in displaying on mobile (text is too small, overflowing the frame), Google may refuse to index it. Optimizing Core Web Vitals metrics like LCP and CLS not only helps rank better, but also helps Googlebot visit the website more often.
API Application Strategy and Automation
For technical SEO, automation is the most effective method to control indexing at scale.
Automation with Google Sheets and Apps Script
A solution A creative solution is to use Google Sheets combined with Apps Script to create a custom index checker. Using the APIs of services like Serper.dev, admins can check thousands of URLs automatically each month and receive alerts when articles are dropped from the index.
Exploit the Google Indexing API
This is a powerful tool to notify Google of new or changed pages instantly.
Compare Sitemap and Indexing API:
Mechanism: Sitemap is a passive method (Google scans itself when it has time), Indexing API is an active method (sends a signal to "push" content).
Latency: Sitemap can take several days; Indexing API is usually processed within 24 hours.
Limitations: Sitemap has no URL limit; The default Indexing API is limited to about 200 requests/day.
Reliability: Sitemap is the standard for all websites; Indexing API is most effective with recruitment data or live events.
Crawl Budget Management
At Tan Phat Digital, we always focus on optimizing data collection budget for business websites to ensure Googlebot's resources are used for the most valuable pages.
Crawl optimization strategy Budget
Handle Redirect Chains: Make sure internal links point directly to the final destination URL to save bot resources.
Remove duplicate content: Use Canonical tags thoroughly.
Analyze server logs (Log File Analysis): Use tools like Botify to understand behavior bot behavior on the page and detecting "crawl traps".
Route to action
Checking for unindexed posts is a meticulous process. Tan Phat Digital proposes the following course of action:
Establish a periodic monitoring system through GSC and automation tools.
Optimize content quality according to E-E-A-T standards to avoid index rejection after collection.
Consolidate technical infrastructure, ensure loading speed and mobile friendliness.
Ultimately, indexing is a game of trust. When Google believes that your website provides real value, the process will happen naturally and quickly. Let's join Tan Phat Digital to build a solid SEO foundation from the smallest technical details.
Share







