Récemment, la question de l'indexation sur Google Search Console (GSC) est devenue un sujet brûlant, intéressant de nombreux administrateurs de sites Web et référenceurs. Le statut de Google non indexé (Non indexé) affecte non seulement la visibilité mais constitue également un signal d'avertissement sur la santé technique du site Web. Cet article, tiré de l'expérience réelle de l'équipe Tan Phat Digital, fournira des instructions détaillées et approfondies pour gérer les erreurs courantes dans le groupe Non indexé.
I. Comprendre le mécanisme d'indexation de Google
Avant de vous lancer dans la gestion des erreurs, vous devez maîtriser le processus par lequel Google interagit avec votre site Web. Tan Phat Digital souligne toujours l'importance de bien comprendre ce mécanisme :
Découverte : Google Bot trouve votre URL.
Exploration : Google Bot accède (analyse) cette URL, télécharge et traite le contenu de la page.
Catégorie d'index) : Si la page est évaluée comme étant de qualité et ne dispose pas de fonctionnalités techniques sérieuses. erreurs, elle sera incluse dans la base de données de Google.
Servir (Server/Rank) : La page a la capacité de s'afficher et de se classer dans les résultats de recherche (SERP).
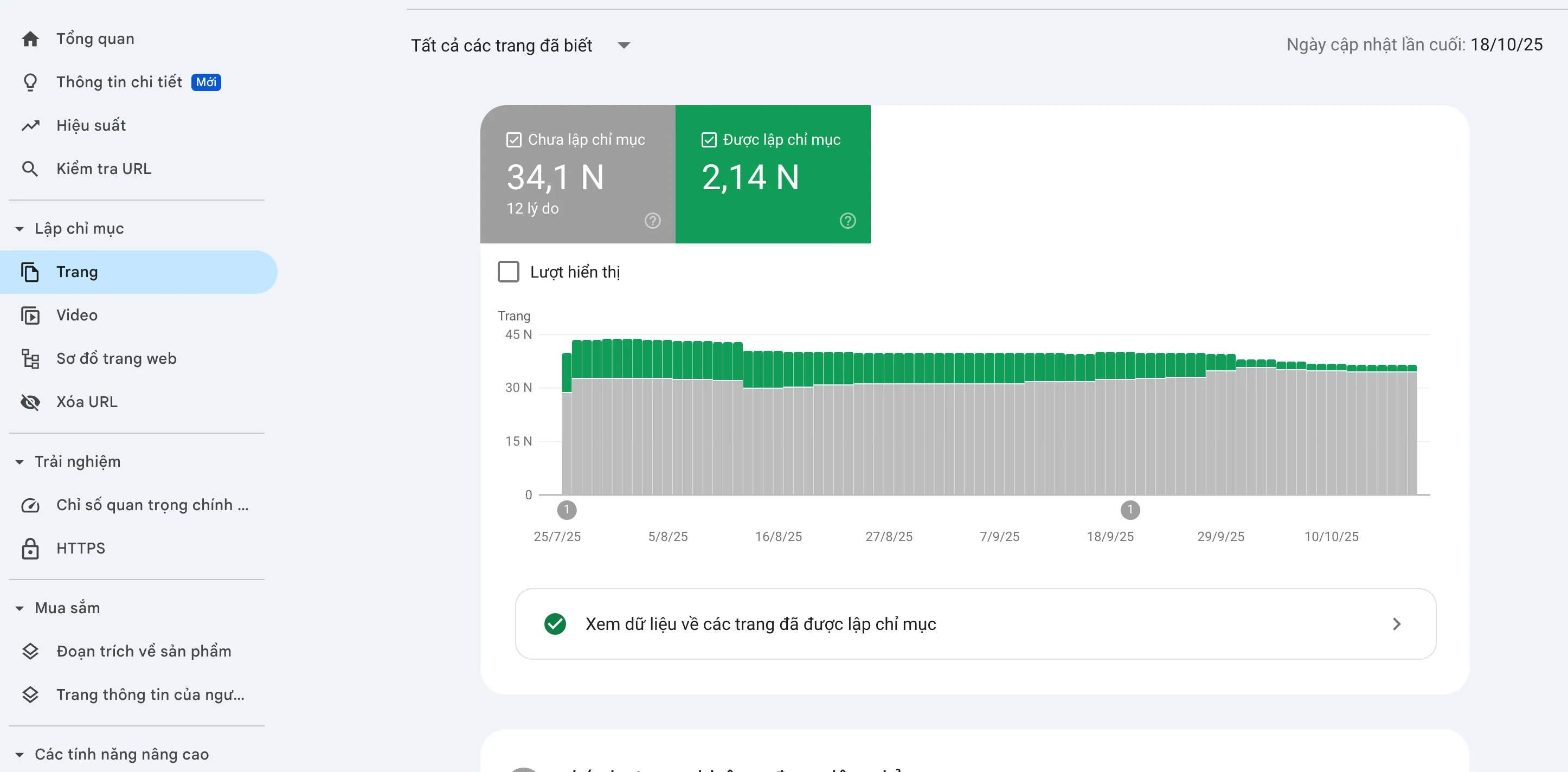
Sur GSC, l'indexation des pages est divisée en deux groupes principaux : Indexé (Groupe vert) et Non indexé (Gris). Groupe).
Principes généraux de traitement pour les groupes non indexés
Classification : Explorez chaque cause spécifique, examinez chaque URL pour déterminer si cette URL doit être indexée ou non.
Traitez la cause première (Cause première) :
Si elle telle est l'intention : Pas besoin de faire quoi que ce soit, ou de bloquer
robots.txtsi cela n'est pas nécessaire.Si une indexation est nécessaire : Rechercher et gérer les erreurs techniques/de contenu. Demandez ensuite à Google de réindexer (Inspecter l'URL à l'aide des outils d'indexation).
Valider : Une fois le traitement terminé, cliquez sur Valider le correctif dans GSC pour permettre à Google de collecter et de relire les dernières données.
II. Analyse détaillée et solution pour chaque cause que Google n'indexe pas
Vous trouverez ci-dessous une analyse détaillée des principales raisons pour lesquelles les pages ne sont pas indexées (Pourquoi les pages ne sont pas indexées ?), ainsi que des étapes de dépannage approfondies de Tan Phat Digital :
1. Découvert – Actuellement non indexé
Description et cause : Google a vu l'URL mais ne l'a pas encore explorée (Exploration). Généralement parce que le budget d'exploration est limité ou que le site Web contient trop de pages sans importance.
Instructions de traitement approfondies :
Optimiser le budget d'exploration : supprimez les liens inutiles du plan du site. Bloquez les pages sans importance (par exemple, les anciennes pages
/tag/,/archive/) avecDisallowdansrobots.txtounoindexpour concentrer les robots sur les pages importantes.Créez des liens internes solides (Liens internes) vers l'index de page nécessaire.
Vérifiez Balises
noindex,robots.txtetSitemappour les erreurs inhabituelles.
2. Exploré – Actuellement non indexé
Description et cause : Google a exploré mais a décidé de ne pas indexer. La raison principale est que l'équipement est considéré comme de mauvaise qualité (faible valeur), comme un contenu léger, des doublons ou des erreurs techniques.
Instructions de manipulation approfondies :
Améliorer le contenu : Évitez le contenu léger (Contenu léger), le contenu en double (Contenu dupliqué). Ajoutez des informations détaillées et uniques qui répondent pleinement à l'intention de recherche (Intention de recherche).
Vérifiez les erreurs techniques : Assurez-vous de bons Core Web Vitals et d'une expérience utilisateur fluide (UX) sur mobile.
Supprimez ou optimisez les pages comportant des erreurs de « cannibalisme de mots clés » (Mot clé Cannibalisation).
3. Exclu par la balise Noindex (Exclus par la balise 'noindex')
- erreur : Supprimez la balise
noindex du code source. Ensuite, la demande d'indexation passe à nouveau par GSC.4. Bloqué par Robots.txt (Bloqué par le fichier robots.txt)
Description et cause : L'URL est bloquée lors de l'exploration (Crawl) par la commande
Disallowdans le fichierrobots.txt.Instructions de manipulation complètes :
Si c'est le cas prévu : Ne faites rien (par exemple, bloquez les dossiers d'administration).
S'il s'agit d'une erreur : Supprimez la directive
Disallowassociée à cette URL dans le fichierrobots.txt. Notez que le blocage des robots empêche uniquement l'exploration et n'est pas garanti pour empêcher l'index à 100 %.
5. En double, Google a choisi une page canonique différente de celle de l'utilisateur (Page en double, Google a choisi une page canonique différente)
Description et cause : L'URL a une balise canonique déclarée (page canonique), mais Google a choisi une meilleure URL à indexer car le contenu est trop similaire ou la balise canonique est mal définie.
Instructions de traitement détaillées. Pour :
Unifier les URL :Corriger les erreurs techniques courantes telles que : les URL avec un "/" à la fin (Trailing Slash) et aucun "/" à la fin. Choisissez un format cohérent pour l'ensemble du site Web.
Réévaluez Canonical : Assurez-vous que le contenu des différentes URL est vraiment différent. S'ils sont identiques, faites confiance au choix de Google ou ajustez correctement la balise canonique.
6. Dupliquer sans canonique sélectionné par l'utilisateur (page en double, l'utilisateur n'a pas sélectionné la page canonique)
Description et cause : L'URL est considérée comme en double sans la balise canonique. Cela arrive souvent avec les pages de pagination (
/page/2), les pagesfeed(/feed/).Instructions de manipulation approfondies :
Attacher Canonical : Balise Canonical à la page principale (par exemple : la page
/page/2pointe Canonical à la page root).Bloquer l'exploration/l'index : Pour les pages inutiles (comme
/feed/), vous pouvez les bloquer complètement avecrobots.txtou utilisernoindexpour économiser le budget d'exploration.
7. Page alternative avec remplacement de la balise canonique appropriée" et aucun index nécessaire.
S'il s'agit d'une erreur : Ajustez la balise canonique, en vous assurant qu'elle pointe vers elle-même s'il s'agit de la page principale.
8. Page avec redirection
Description et cause : L'URL est redirigée (301/302) vers une autre URL. Google indexera l'URL de destination.
- Assurez-vous que l'URL de redirection est une URL valide.
9. Erreur de redirection
Description et cause : Erreur grave due à une chaîne de redirection trop longue, redirection en boucle (A $\rightarrow$ B $\rightarrow$ A), ou redirigez vers une URL invalide.
Solution complète :
Vérifiez la chaîne de redirection avec des outils spécialisés
Supprimez les redirections en boucle.
Assurez-vous que l'URL de destination de la redirection renvoie un 200 OK code.
10. Erreur de serveur (5xx)
Description et cause : L'URL renvoie le code d'erreur de serveur 5xx (500, 503, 504...) Le serveur est instable ou surchargé.
Complet. Solution :
Contactez le fournisseur d'hébergement pour vérifier et mettre à niveau les performances du serveur.
Assurez-vous que l'URL renvoie le code 200 OK (Succès), demandez à nouveau l'index.
11 Introuvable (404)
Description et Cause : L'URL n'existe pas, retournez le code 404.
Action complète :
Si l'URL n'est plus nécessaire : Ne faites rien. déplacé vers une nouvelle page, créez une redirection 301 vers la nouvelle page.
Tan Phat Digital recommande d'exploiter les 404 pour l'UX en créant une page 404 conviviale.
Soft 404
Description et cause : l'URL n'a pas de contenu principal (par exemple, une page de produit vide, une catégorie en rupture de stock) mais renvoie le code 200 OK au lieu de 404. Google pense que cette page devrait être 404.
Action correcte à :
Si la page est toujours dans utiliser : Ajoutez du contenu, des produits ou une redirection 301 vers une page avec un contenu équivalent.
Si la page n'est plus utilisée : Assurez-vous qu'elle renvoie un code 404 Not Found ou 410 Gone et bloquez l'exploration avec
robots.txtsi nécessaire défini.
13. Indexé, bien que bloqué par robots.txt À :Si le blocage est NÉCESSAIRE : Supprimez la directive Disallow dans robots.txt, puis ajoutez la balise noindex à cette page. Cela permet à Google Bot de lire la balise noindex et de supprimer la page de l'index. Une fois la page désindexée, vous pouvez rajouter Disallow pour économiser le budget d'exploration.
Si le blocage n'est PAS nécessaire : Supprimez la directive Disallow dans robots.txt afin que Google Bot puisse explorer et mettre à jour le contenu normalement.
Si le blocage est NÉCESSAIRE : Supprimez la directive Disallow dans robots.txt, puis ajoutez la balise noindex à cette page. Cela permet à Google Bot de lire la balise noindex et de supprimer la page de l'index. Une fois la page désindexée, vous pouvez rajouter Disallow pour économiser le budget d'exploration.
Si le blocage n'est PAS nécessaire : Supprimez la directive Disallow dans robots.txt afin que Google Bot puisse explorer et mettre à jour le contenu normalement.
III. Principes techniques de référencement pour prendre en charge l'indexation
Pour garantir le bon déroulement de l'indexation et éviter de tomber dans le groupe Non indexé, Tan Phat Digital recommande de mettre en œuvre les optimisations techniques suivantes :
Robots.txt et Noindex : Vérifiez régulièrement le fichier
robots.txtet le code source de la page pour vous assurer qu'il n'y a pas d'ordres de blocage erronés. Utilisez l'outilrobots.txt Testerdans GSC.Plan du site XML :
Créez et mettez à jour périodiquement le fichier XML du plan du site.
Incluez uniquement les URL qui nécessitent l'index Google dans le plan du site.
Envoyez le plan du site à GSC pour informer Google de la structure. site Web.
Liens internes (Inlink) : Construisez un réseau de liens internes raisonnable, en utilisant un texte d'ancrage descriptif. Aide Google Bot à Découvrir facilement des pages plus profondes.
Vitesse et expérience : Garantit une vitesse de chargement rapide des pages et une interface adaptée aux mobiles.
Qualité du contenu : Garantit que le contenu est unique, approfondi et répond aux Intentions de recherche extrêmement dominantes des utilisateurs.
IV. Foire aux questions (FAQ) sur l'erreur de non-indexation de Google
1. Après avoir corrigé l'erreur, combien de temps faut-il pour que la page soit réindexée ?
Réponse : Le temps de réindexation dépend du budget d'exploration, du niveau de réputation du nom de domaine et de la gravité de l'erreur.
Il varie généralement de quelques jours à quelques jours. semaine.
Tan Phat Digital vous recommande d'être patient, de vérifier régulièrement et d'effectuer Valider le correctif après avoir terminé la réparation.
2. Toutes les URL du groupe Non indexées doivent-elles être traitées ?
Réponse : NON. Le groupe Non indexé (gris) existe toujours sur n'importe quel site Web et est considéré comme des Avis et non strictement des Erreurs.
L'objectif est de garantir que toutes les URL importantes et nécessaires au référencement doivent être dans le groupe Indexé.
3. Quelle est la différence entre « Soft 404 » et « Not Found (404) » ? (Format de liste de comparaison)
Soft 404 (Soft 404) :
Code d'état HTTP : 200 OK (Succès).
Contenu affiché : Presque aucun contenu principal (page vide, erreur de chargement).
Note Google : Page devrait être 404 mais il est indiqué 200. Il s'agit d'une erreur technique qui doit être corrigée.
Introuvable (404 dur) :
Code d'état HTTP : 404 introuvable.
Contenu affiché : Page d'erreur 404.
Avis Google : La page n'existe pas. C'est l'état correct.
4. Qu'est-ce que le budget d'exploration et comment l'optimiser ?
Réponse : Le budget d'exploration est le nombre de pages que Google Bot est disposé et capable d'explorer sur votre site Web au cours d'une certaine période de temps.
Méthode optimale :
Augmentez la vitesse de chargement des pages (temps de réponse du serveur).
Bloquer
robots.txtinutile pages.Utilisez la balise
noindexpour les pages avec un contenu léger.Contrôlez les redirections (chaîne de redirection).
La gestion des erreurs de non-indexation de Google nécessite une compréhension approfondie des techniques et des mécanismes de référencement des activités de Google. Vous devez comprendre clairement la structure des URL de votre site Web, classer avec précision les pages qui doivent être indexées et ne doivent pas être indexées, puis appliquer la solution la plus complète. Ne vous inquiétez pas trop du numéro Non indexé, concentrez-vous sur la qualité des pages nécessaires et assurez-vous qu'elles sont dans le groupe Indexé.
Vous rencontrez des difficultés à gérer des erreurs techniques complexes sur GSC et avez besoin d'une solution approfondie ?
Tan Phat Digital avec une expérience approfondie en référencement technique et en audit de site Web vous aidera à :
Analyser minutieusement les erreurs non indexées, identifier la cause première.
Optimiser la structure du site Web et le budget d'exploration.
Assurer que la vitesse et les performances du site Web répondent aux normes de Google.
S'il vous plaît Contactez Tan Phat Digital immédiatement pour obtenir des conseils et des solutions de référencement complètes, aidant votre site Web à toujours être indexé et classé de manière optimale par Google !
Partager