私。戦略概要: 新しい AI 見積エコノミー
I.A.パラダイム シフト: ランキング (SEO) から引用 (LLMO) へ
ChatGPT や AI アシスタントなどの大規模言語モデル (LLM) の台頭により、ユーザー情報発見のプロセスは根本的に変化しました。消費者は、ランク付けされたリンクの従来のリストを選別する代わりに、直接、集約された、会話形式の回答を得るために AI ツールに目を向けることが増えています。
この変更により、コンテンツの目標が再定義されます。目標は、検索結果からクリックされることだけではなく、AI 応答の真の引用となることです。これにより、大規模言語モデル最適化 (LLMO) と呼ばれる、最適化のための新しい要件が作成されます。
このレポートは、20 業界にわたる 129,000 以上のドメインと 216,000 以上のページを分析した SE Rank による詳細な調査の結果を総合して、ChatGPT が Web サイトを引用することを選択する特定のシグナルを特定します。これらの調査結果は、AI 向け SEO に関する多くの仮定に疑問を投げかけ、持続的な権威と評判のシグナルが依然として普及していることを強調しています。
I.B.洗練さと方法論: LLM 信号における相関と因果関係
ChatGPT によるソースの選択はランダムなプロセスではありません。これは複雑な信頼性検証メカニズムです。引用はユーザーの監視メカニズムとして機能し、LLM の応答を調べて、それがユーザーの期待や議論と一致するかどうかを判断できるようにします。
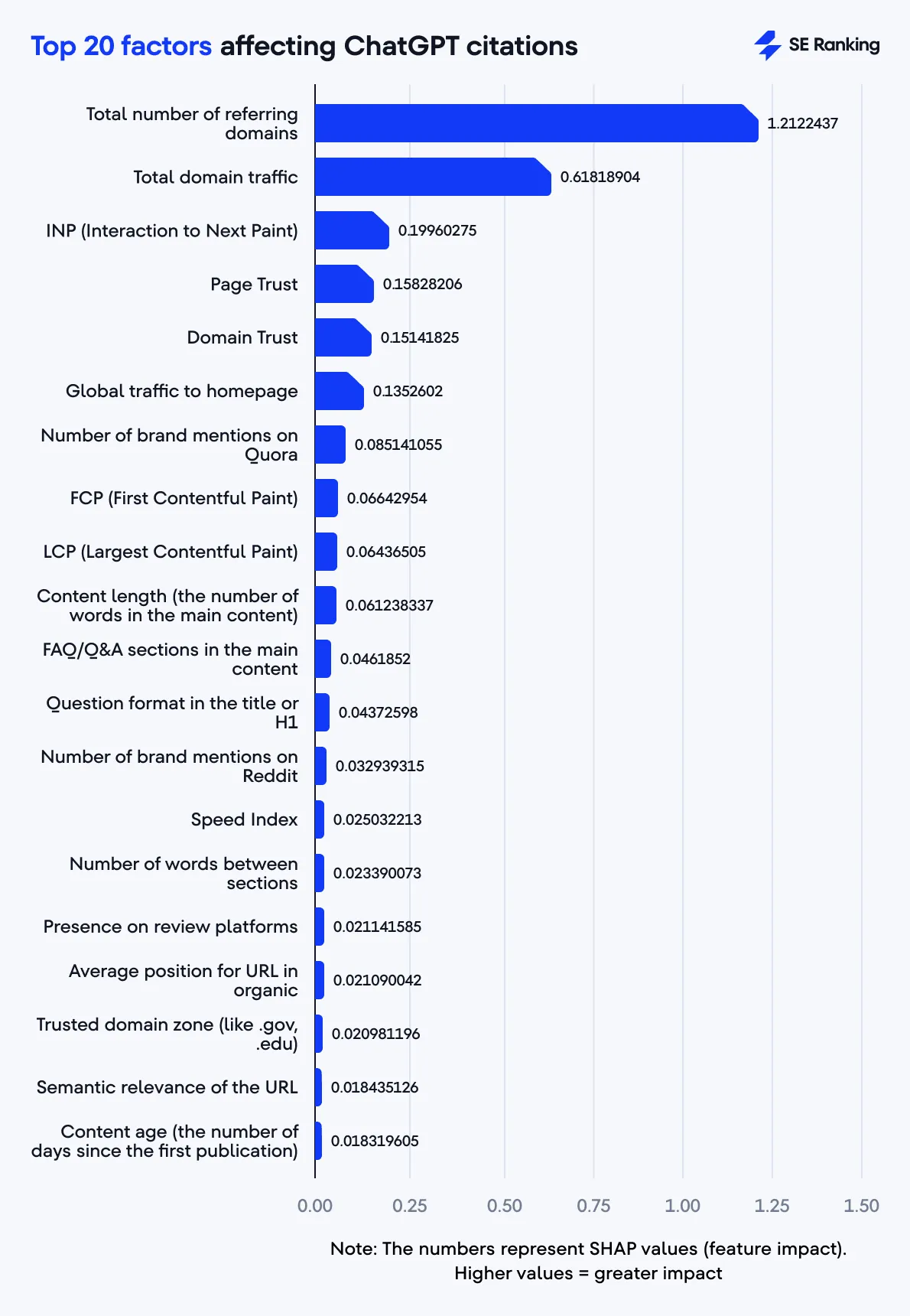
広範な分析により、ChatGPT は Google と非常によく似たシグナルを使用しているが、いくつかの新しい優先順位が付けられていることがわかりました。 Google のオーガニック検索ランキングと ChatGPT からの引用の間の有意な相関関係は、その代表的な例です。 Google オーガニック検索で平均 1 位から 45 位にランク付けされたページは平均 5 件の引用を受けましたが、64 位から 75 位にランク付けされたページではわずか 3.1 件の引用しかありませんでした。
これは、LLM が Google での高い可視性を検証済みの信頼性の代替手段として考慮していることを示しています。 AI モデルは新しい信頼指標を発明しません。彼らは、数十年にわたるウェブ品質評価 (つまり、Google のインデックスとランキングのシグナル) を効果的に活用して、信頼できるコンテンツを除外しています。これは、LLMO で成功するには、基礎的な SEO が依然として必須であり、オプションではないことを意味します。
II.基礎の柱: 強力なドメイン権限 (要素 1 ~ 5)
次の 5 つの要素は、ChatGPT による引用検討の対象となるサイトの適格性を決定する一次審査メカニズムとして機能します。 ChatGPT に引用されるには、評判が重要な要素です。
要素 1: バックリンク プロファイルの強度 (参照ドメインの数)
バックリンクは、ChatGPT の引用にとって最も強力な要素であると判断されます。リンク ドメイン (RD) の数が多いサイトは、常に弱いリンク プロファイルよりもパフォーマンスが優れています。定量的分析は、LLM エコシステムが Web グラフから独立していないことを示しています。リンクの公平性は信頼と権威の重要なシグナルとして機能し、歴史的な信任投票として機能します。
要因 2: 全体的なドメイン信頼スコアが高い
ドメイン信頼スコアが高い (例: 90 以上) ウェブサイトは、引用される可能性が 4 倍近く高くなります。この定量的な結果は、LLM には、より広範なウェブがソースを信頼しているという強力で測定可能な証拠が必要であることを裏付けています。これにより、経験、専門知識、権限、信頼性 (E-E-A-T) の抽象的な概念が、AI が使用できる定量化可能な指標に変換されます。
要因 3: 大幅なオーガニック ドメイン トラフィック
ドメイン トラフィックは重要度で 2 番目にランクされます。ただし、分析によると、顕著な相関関係は、ドメインの月間訪問数が 190,000 というしきい値を超えた後にのみ現れ、訪問数が 1,000 万を超えるドメインでは平均 8.5 件の引用に達することが示されています。トラフィックは行動の検証として機能し、有用で満足のいくコンテンツ、つまり持続的な品質のシグナルを示します。
要素 4: 高いオーガニック Google ランキング
Google オーガニック検索における URL の平均ランキングと ChatGPT 引用との相関関係は明らかです。このシグナルは、SEO と LLMO の共生関係を強化します。コンテンツが Google の品質評価で良好なパフォーマンスを示した場合、LLM 引用元となる可能性が高くなります。
要素 5: 絶対的な優位性よりもコンテキストの関連性が重要
権威は入力フィルターですが、LLM の可視性は絶対的な権威よりもコンテキストの関連性と情報の正確さに依存します。絶対的に権威の高い指標 (高い DR/DA など) は、コンテンツがクエリと文脈的に関連していない場合、弱い相関または負の相関を示す可能性があります。
ChatGPT の引用率に対する権威測定の定量的影響 (リスト比較分析)
参照ドメイン (RD):
最低範囲 (RD 2,500 未満): 平均 1.6 ~ 1.8 引用
最高範囲 (350,000 RD 以上): 平均 8.4 引用。
引用影響力: 最も強い相関関係 (一次フィルター)。
引用の影響:高い相関性 (行動の確認)。
自然な Google ランキング:
最低範囲 (64 ~ 75 位): 平均 3.1 引用。
最高範囲 (1 ~ 45 位): 平均 5.0
引用の影響力: 相関関係が強い (品質代表者)。
Ⅲ.信頼乗数: E-E-A-T と外部検証 (係数 6 ~ 10)
AI モデルは、サイトの実際の権威と評判を証明するために外部シグナルを探します。これらの要素は、LLM にとって重要な社会的証明を提供します。
要素 6: 証明可能な E-E-A-T シグナルとケーススタディ
E-E-A-T (経験、専門知識、権威性、および信頼性) は、AI システムが信頼性と権威を評価するための中核基盤です。 AI 時代の権威は Web サイトを超えて広がります。コンテンツは公式ガイダンスに基づいたものであり、独自の調査や専門家のビデオで補足される必要があります。
現実の証拠 (ケーススタディ) の統合: 専門分野では、現実世界のテストと結果のケーススタディを共有するアナリスト会社や専門家が、LLM によって権威の情報源として特定されることがよくあります。専門家に執筆やレビューを依頼し、研究を引用し、コンテンツを最新の状態に保つことが不可欠です。
著者の透明性は重要な信頼性基準であり、著者の名前、経歴、連絡先情報の提供が必要です。
要素 7: Reddit と Quora での言及によるコミュニティの検証
Reddit または Quora で頻繁に言及されるドメインは、引用される可能性が 4 倍高くなります。 AI はコミュニティのディスカッションやレビューを強力な信頼のシグナルとみなしているようです。これは、LLM が Reddit のような影響力のあるコミュニティが本物の詳細なディスカッションを主催していることを認識していることを示しています。
要素 8: 業界レビュー サイトおよびディレクトリでの存在
トランザクションまたは B2B クエリの場合、G2、Capterra、Trustpilot などのサイトに存在すると、引用される可能性が 3 倍になります。 AI は教育コンテンツとピアレビューを統合して、包括的な洞察を形成します。
要素 9: コンテンツの更新頻度と鮮度
新しく更新されたコンテンツ (3 か月以内) は、引用される可能性がほぼ 2 倍になります。これは、LLM が直面している事実の正確さの課題に対処するために重要です。 AI モデルには、コンテンツが歴史的に正確であるだけでなく、今日でも信頼できるという証拠が必要です。
要素 10: 所有権と資金提供に関する透明性
透明性は、LLM が推測しようとする重要な信頼性基準です。特に「Your Money or Your Life」(YMYL)トピックの場合、所有権と資金提供を明確に開示することで、根底にある信頼性のシグナルを強化することができます。
IV. LLM 抽出を容易にするためのコンテンツの構造化 (要素 11 ~ 15)
これらの要素は、機械解析用にコンテンツを最適化し、精度と摩擦を最小限に抑えた真実の抽出に重点を置いています。
要素 11: Answer Capsules の実装 (カプセル)
アンサー カプセルはこのサイトで最も共通しているものであり、引用された投稿の 72.4% に表示されています。これらのカプセルは多くの場合、タイトルの直後に配置され、直接的で自信に満ちたステートメントを提供し、真実を優先します。このカプセル テキスト内のリンクを最小限に抑えること、特に内部リンクと外部リンクを省略することが重要です。これは、ChatGPT からの参照率の向上に関連するためです。
要素 12: オリジナル データと所有データを強調する
オリジナル データまたはブランド所有のインサイトは 2 番目に強力な差別化要因であり、引用されたページの 52.2% に現れています。コンテンツが飽和した状況では、独自の洞察によってコンテンツの独自の価値と専門知識が検証されるため、重複を最小限に抑え、引用の可能性を最大化できます。複雑なデータ抽出を最適化するには、明示的なデータ構造 (JSON スキーマなど) を使用すると、抽出エラーを大幅に減らすことができます。
要素 13: 包括的なコンテンツの深さ (長文)
長さが 2,900 ワードを超える長文ページでは、大幅に多くの引用が集まります (短いコンテンツの場合は 5.1 倍、3.2 倍)。長く詳細なコンテンツにより、LLM はさまざまな証拠から情報を統合し、詳細かつ厳密な帰属を必要とする「詳細な」タスクをサポートできます。
要素 14: 最適な本文の長さ、階層構造、質問のようなタイトル
明確な構造は、ページ解釈モデルに役立ち、引用数を大幅に増やします。具体的には、長さが 120 ~ 180 ワードのコンテンツ セクション (見出し間の単語数) が最もパフォーマンスが良く、非常に短いセクションと比較して引用数が 70% 増加しました。
質問フォームのタイトルと集中的な FAQ を活用する: LLM は、ユーザーのクエリに一致する簡潔で正確な回答を探します。
FAQ 戦略: FAQ は、重要な問題点に対処できる意図の高いページまたは場所にのみ追加します。
短い: 答えは短く、要点を絞って、役立つものにしてください。
要素 15: データ形式 (リストとテーブル)
番号付きリスト (順序が重要な場合) と箇条書きリスト (順序がそれほど重要でない場合) の使用が必要です。同様に、複数のデータ ポイントを比較するにはテーブルを使用する必要があります。構造化フォーマットにより、LLM 文書解析ツールによってコンテンツが体系的に処理される可能性が高まります。
コンテンツの最適化と引用の目標 (比較リスト分析)
回答カプセル (回答カプセル):
LLM 最適化目標 (AIO): ダイレクト レスポンスの抽出と集約。
サポートメカニズム/データ: 引用された記事の 72.4% が使用しています。最小リンク優先度。
引用の影響: 高い信頼度を抽出します。
所有データ:
LLM 最適化目標 (AIO): 独自の検証可能な主張を提供します。事実。
サポート データ/メカニズムのサポート: 引用記事の 52.2% に独占的な情報が含まれています。
サポート:最適な長さは 120 ~ 180 ワードです。明確な階層。引用への影響: 低摩擦処理。
データ形式:
LLM 最適化目標 (AIO): 詳細の曖昧さが少なくなります。抽出。
サポートメカニズム/データ: 書籍/ボードのリストの簡潔さ。明確なタイトル。
2,900 を超える高引用単語。引用の影響: 包括的な範囲。
V. LLM の技術的衛生とクローラビリティ (要素 16 ~ 18)
これらは、LLM クローラーがサイトにアクセスし、高品質であると認識できることを保証するために必要な運用要件です。
要素 16: ページ速度とコア Web バイタル (INP、LCP、CLS)
ページ読み込み速度は、Web サイトの AI の可視性に大きな影響を与えます。読み込みが遅い Web サイトは信頼性が低いと見なされ、引用される可能性が低くなります。速度が低いと、Web スクレイピングを実行するときに AI モデルがコンテンツのインデックスを完全に作成できない可能性があります。 Core Web Vitals (LCP、INP、CLS) は、優れたユーザー エクスペリエンスを評価するために AI システムが求める中核的なランキング要素であるため、最適化は基本です。
要素 17: 明確なサイト構造とクロール能力
LLM 可視化には、強固な技術的基盤が必要です。これには、明確な階層、定期的に更新される包括的な XML サイトマップ、AI クローラーを妨げる可能性のある技術的障壁 (過剰なボット ブロックなど) を備えたクリーンで論理的なサイト構造を維持することが含まれます。
要素 18: モバイルの最適化と HTTPS セキュリティ
モバイルの最適化と HTTPS セキュリティは必須のプラットフォーム標準です。これらの要素に欠陥がある場合は、信頼レベルが低く、ユーザー エクスペリエンスが劣悪であることを示しており、その情報源は直ちに高品質の AI 評価から失格となります。
VI.戦略と噂やプレフィックス衛生の区別 (要素 19 ~ 20)
効果的な LLMO 戦略には、実際に影響を与える要因にリソースを集中させ、効果がないと証明された戦術を無視する必要があります。
要素 19: LLMs.txt とスキーマの一般的な FAQ の無視一般
SE Rank の調査では、AI クローラーをガイドするために推奨されるファイルである LLMs.txt ファイルには影響がないことが示されています。 Google、OpenAI、Anthropic などの主要な AI サービスはこのプロトコルを使用していないため、効果がありません。同様に、FAQ スキーマのマークアップは、引用との限定的な相関関係を示します。これは、LLM が答えを抽出するための単純なディレクティブやマークアップではなく、自然言語処理と洗練されたコンテンツ構造 (要素 14) に依存しているという点を強化します。
要素 20: 過剰な最適化 (タイトル、URL) とプレフィックス (メタ) の最適化を避ける
AI はキーワードの詰め込みよりも明確なトピックのシグナルを優先するため、URL とタイトルの過剰な最適化は引用に悪影響を与える可能性があります。従来のパターン マッチング アルゴリズム用に設計された過度のキーワード操作は、品質の低下を示し、LLM が自信を持って核となるトピックを抽出する能力を妨げます。
プレフィックスの最適化 (メタ タグ、キーワード、抜粋):
メタ キーワード タグ: Google で無視されるのと同様、最新の AI システムでは完全に無視され、LLMO には利益がありません。
メタ ディスクリプション (抜粋): 直接的な引用要素ではありませんが、明確で説得力のある説明は、従来の検索結果からのクリックスルー率 (CTR) の向上に役立ち、それによって AI が評価する信頼シグナルであるトラフィック (要素 3) を間接的にサポートします。
タイトルと URL: 明確さ、簡潔さ、文脈の関連性に重点を置きます。
VII.A. 20 ポイントの LLM 引用チェックリスト (ネストされたリスト)
強力な権限 (信頼基盤)
バックリンク プロファイルの強度 (RD カウント)
全体的なドメイン信頼スコアが高い
大幅なオーガニック ドメイン トラフィック
オーガニック Google ランキングの上位 (代表的)
コンテキストの関連性の最適化
E-E-A-T シグナル (専門家、ケーススタディ)
外部検証 (社会的証明)
著者の透明性
コミュニティ検証Reddit/Quora
業界レビュー サイトでの存在
所有権と資金に関する透明性
コンテンツの正確性 (抽出可能性)
Answer Capsule の実装
オリジナルおよび独自データのマーキング
包括的なコンテンツの深さ (>2,900 ワード)
最適なコンテンツ構造と質問形式のタイトル
データ形式 (リストと表)
技術と新規性 (輸送衛生措置)
物理コンテンツの更新 (更新サイクル)
ページ速度とコア ウェブ バイタル (INP/LCP)
クリーンなサイト構造とクローラビリティ
モバイルの最適化と HTTPS セキュリティ
戦略的焦点 (噂の反論)
過剰な最適化とプレフィックス (メタ) 最適化を避ける
VII.B.引用後のコンバージョンの最適化
LLMO の最終目標は、貴重なトラフィックを Web サイトに誘導し、それらをコンバージョンに導くことです。 ChatGPT の引用により、あなたのブランドは非常に評判の高い地位にあります。したがって、ユーザーの次の移動に向けてランディング ページを最適化することが不可欠です。
CTA 戦略:
明確な CTA: AI はリンクされていない直接コンテンツ (回答カプセル) を引用することがよくありますが、ページの残りの部分には、ユーザーを認識から行動に導くための適切に設計された CTA (例: 「完全なレポートをダウンロード」または「無料相談のリクエスト」) を含める必要があります。
ランディング ページ エクスペリエンスの重要性: AI 見積もりが生み出した信頼を失わないように、ランディング ページがコア ウェブ バイタル (要素 17) やモバイル最適化 (要素 19) などの技術的要素を満たしていることを確認してください。
VIII. LLMO と戦略的投資の将来 (詳細な結論)
129,000 ドメインの調査からのデータ分析は、ChatGPT の引用を獲得することが簡単な「AI トリック」ではないことを示しています。代わりに、LLM 固有の信頼性とコンテキストの正確さのシグナルに支えられた、Web 品質の基本を一貫して適用した結果です。 ChatGPT の引用モデルは、わずか数か月でソースの多様性を約 80% 増加させ、ユーザー エクスペリエンスと出力品質が継続的に向上する傾向を示しています。
戦略的投資要件:
LLM 最適化 (LLMO) の成功には、秩序ある戦略的資本配分が必要です:
持続可能な権限を優先する:高品質のリンク構築やオーガニック トラフィックなど、主に長期的で反証不可能な要素 (要素 1 ~ 6) に資本を配分します。
現実の評判シグナルに投資する:対話マーケティングと評判管理戦略を統合します (要素 7 ~ 10)。 Reddit、Quora、業界レビュー サイトでの積極的な存在は、AI が信頼しているという社会的証拠です。
コンテンツ構造標準の強制: 回答カプセルの書式設定、独自データの使用、最適な段落構造に関するライターのトレーニングなど、正確性と抽出可能性を確保する編集プロセス (要素 11 ~ 15) に投資します。
LLMO の最終目標は、信頼できる最新の情報源であり、LLM が選択するほど完全に構造化されている情報源になることです。絶大な自信。これらの柱への一貫したコンプライアンスと投資により、ウェブサイトが Google で上位にランクされるだけでなく、AI 回答でもランク付けされ、Tan Phat Digital が品質に重点を置くことで実現してきたように、持続可能な成長を求める企業に大きな競争上の優位性をもたらします。絶対的な品質と権威。
シェア